Advanced search settings
In addition to the fundamental search settings, the Model Finder module also provides advanced settings that allow you to specify whether the polarity of the edges in a model differs from those in occurrences, how much or little separation between occurrences is permitted, as well as other information.
Polarity
The polarity of an edge indicates whether edges occur as transitions from light to dark or vice versa. When the polarity of edges in the target might be different from those of the model (for example, due to shadows), you should specify the expected polarity using MmodControl() with M_POLARITY. This control type allows you to specify whether edges present in the model and in the occurrence have the same, the reverse, either of these, or a mixture of both polarities.
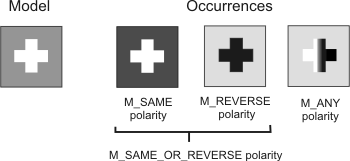
The default polarity setting for models in an M_GEOMETRIC or M_GEOMETRIC_CONTROLLED type of Model Finder context is M_SAME. For models in an M_SHAPE_CIRCLE type of Model Finder context, the default polarity setting is M_SAME_OR_REVERSE.
The polarity setting can be useful when dealing with adverse lighting conditions where dark shadows can cause edges to vary in polarity.

Radii deviation tolerance
For a model in an M_SHAPE_CIRCLE type of Model Finder context, you can adjust the sagitta tolerance (M_SAGITTA_TOLERANCE) to limit the allowable radii deviation from a perfect circle. Given the other specified constraints for the model, there is a certain amount of deviation that can be permitted. Using M_SAGITTA_TOLERANCE, you can restrict this amount. Essentially, M_SAGITTA_TOLERANCE establishes the search area in which to consider active edges for an occurrence at a given scale; a best fit circle is then fit within these active edges.
The sagitta tolerance allows you to specify how perfectly circular you want the occurrence to be. This allows you to find circular shapes that do not have a constant radius over the full angular range of the contour. For instance, an elliptical shape could be identified as a potential occurrence if the radii variation is within the bounds specified using M_SAGITTA_TOLERANCE. In addition, shapes that are circular in nature but have rough or noisy edges, such as a bottle cap, could be identified as a potential occurrence. If the occurrence in the target is expected to be perfectly circular with a constant radius across the full angular range, you could safely set the sagitta tolerance close to 0.0%. Whereas, if the typical occurrence within a target is not perfectly circular, this control type should be increased from the default value of 25.0% to accurately detect instances of the occurrence within the target. The upper and lower bounds of the search area constrained by the sagitta tolerance vary with scale.
The following two images deal with trying to identify an elliptical shape as an occurrence of a circle. In the image on the left, you can see that the algorithm found the edge of the ellipse but, because the selected sagitta tolerance was set too low, the center of the search area does not coincide with the center of the occurrence being sought. In the image on the right, you can see that the ellipse falls completely within the upper and lower bounds of the search area established by the sagitta tolerance, and as such the occurrence being sought is found.
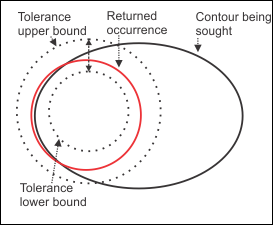
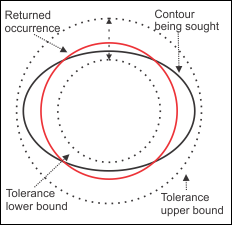
The model coverage for the image on the left would be relatively low, never reaching 50%. Whereas the model coverage for the image on the right would be near 100%. This is because the contour being sought is completely within the bounds of the search area defined by the sagitta tolerance for the image on the right; so, the entire contour is considered an active edge of the occurrence. For the image on the left, the bounds of the search area defined by the sagitta tolerance do not encompass the ellipse entirely, so only the portion of the contour within the bounds is considered as an active edge of the occurrence. In contrast, the fit error for the image on the left would be small, while the image on the right would have a much higher fit error. This is because the returned occurrence (best fit circle) for the image on the left coincides closely with the portion of the ellipse within the search area, whereas the returned occurrence for the image on the right only has 4 intersection points with the ellipse.
The following images demonstrate a situation where the outline of a flower needs to be identified as an occurrence. In the image on the left, the sagitta tolerance was set too low, causing the algorithm to identify the outline of the petal as being the circular shape being sought. In the image on the right, the sagitta tolerance was set to an appropriate level, and the average outline of the flower was identified as an occurrence.
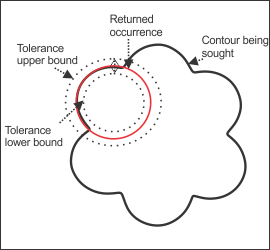
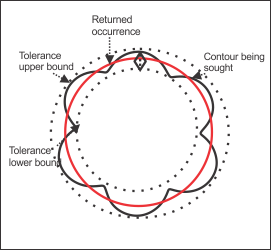
The model coverage for the image on the left would be roughly 50% while the coverage for the image on the right would be near 100%. Much like for the elliptical example, the contour being sought is completely within the bounds of the sagitta tolerance for the image on the right; while for the image on the left, the bounds of the sagitta tolerance encompass only one petal of the flower. The fit error for the image on the left would be much lower than that for the image on the right. This is because the returned occurrence for the image on the left corresponds strongly with the portion of the flower within the search area; while for the image on the right, the returned occurrence does correspond closely with the contour being sought, but due to the nature of the contour (not perfectly circular), there will always be a fit error.
The following images demonstrate cases where the sagitta tolerance was set to an appropriate level and where it was set to be too high. The image on the left demonstrates a case where the sagitta tolerance was set to an appropriate level and the occurrence of the circular shape was accurately detected. The image on the right demonstrates a case where the sagitta tolerance was set to an exceedingly high level. It can be seen that the upper bound of the sagitta tolerance covers the edge of an adjacent rectangle, and as such, the edge of the rectangle is misidentified as being a part of the occurrence being sought.
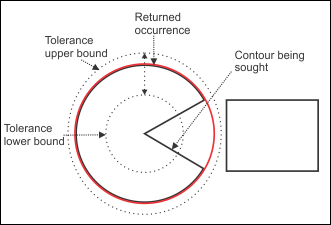
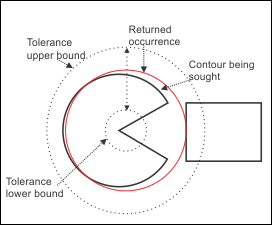
Although the model coverage would be high, over 75%, in the two images above, the model coverage for the image on the right would actually be higher than that on the left. This is because the algorithm detects the edges of the rectangle as being the missing edges. There are still some edges which are missing for the model on the right (from +/- 25 o to +/- 30 o ); this means that the model coverage will never be 100%. The fit error for the image on the left would be very low since the model's active edges coincide highly with the edges of the contour being sought. In contrast, the fit error for the image on the right would be higher since the occurrence does not have as close a fit with the active edges.
Separation
You can specify the minimum amount of separation from other occurrences (of the same model) for an occurrence to be considered distinct (a match). In essence, this determines what amount of overlap by different model occurrences is possible.
You can set the minimum separation for four criteria, which are: the X-position, Y-position, angle, and scale. These can be set for each individual model in your Model Finder context. For an occurrence to be considered distinct from another, only one of the minimum separation conditions needs to be met. For example, if the minimum separation in terms of angle is met, then the occurrence is considered distinct, regardless of the separation in position or scale. However, each of these separation criteria can be disabled (M_DISABLE) so that it is not considered when determining a valid occurrence.
DISTINCT OCCURRENCE = (Separation in X) OR (Separation in Y) OR (Separation in Angle) OR (Separation in Scale).
The minimum positional separation (MmodControl() with M_MIN_SEPARATION_X and M_MIN_SEPARATION_Y) determines the minimum distance between the found positions of two occurrences of the same model. This separation is specified as a percentage of the model size at the nominal scale (M_SCALE). The minimum value that you can set for M_MIN_SEPARATION_X and M_MIN_SEPARATION_Y is 0, which means that there is no minimum distance needed for occurrences to be distinct; all occurrences will be considered distinct regardless of other separation conditions. You can set very large values for M_MIN_SEPARATION_X and M_MIN_SEPARATION_Y; if they are large enough, for example, if the values are larger than the size of the image, it is equivalent to setting this separation condition to M_DISABLE since this condition will never be met. In this case, whether an occurrence is distinct or not will depend on the other separation conditions.
The minimum angular separation (M_MIN_SEPARATION_ANGLE) determines the minimum difference in angle between occurrences. This value is specified as an absolute angle value. The default value is 10.0 o . The minimum value that you can set for M_MIN_SEPARATION_ANGLE is 0, which means that there is no minimum difference in angle needed for occurrences to be distinct; all occurrences will be considered distinct regardless of other separation conditions. The maximum absolute angle difference is 180 degrees. For a diagram of the delta convention used in MIL, see the Angle and angular range subsection of the Position, angle, and scale section earlier in this chapter. If the angle is larger than 180, an error will be returned. At 180 degrees, it is equivalent to setting this separation condition to M_DISABLE. In this case, whether an occurrence is distinct or not will depend on the other separation conditions. It is to be noted that M_MIN_SEPARATION_ANGLE is not supported for models defined with an M_SHAPE_CIRCLE type of Model Finder context.
The minimum scale separation (M_MIN_SEPARATION_SCALE) determines the minimum difference in scale between occurrences, as a scale factor. The default value is 1.1. The minimum value that you can set for M_MIN_SEPARATION_SCALE is 1, which means that there is no minimum difference in scale needed for occurrences to be distinct; all occurrences will be considered distinct regardless of other separation conditions. The maximum value that you can set for M_MIN_SEPARATION_SCALE is 4, which is equivalent to setting this separation condition to M_DISABLE. In this case, whether an occurrence is distinct or not will depend on the other separation conditions.
The four criteria are summarized below in equation form.

The following example illustrates the four separation criteria; an arrow represents two occurrences of the same model and the various types of separation possible.
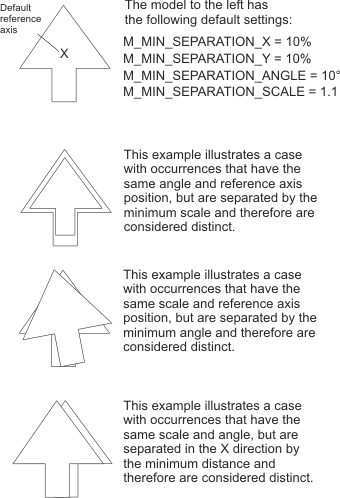
It should be noted that for a model to be found, the number of visible edges in the occurrence must be sufficient to provide a match according to your acceptance levels.
Shared edges
You can choose to allow occurrences to share edges, using MmodControl() with M_SHARED_EDGES set to M_ENABLE. Otherwise, edges that can be part of more than one occurrence are considered part of the occurrence with the greatest score. For example, in the illustration below, two occurrences of two simple models share a common edge. With shared edges enabled, these occurrences would have perfect scores.
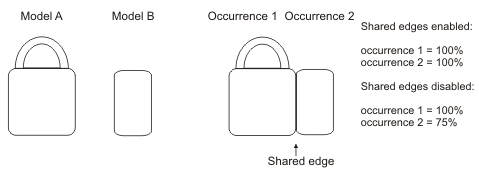
However, with shared edges disabled (default), the shared edge would be considered part of occurrence 1, since it has the greater score; the score of occurrence 2 would be subsequently reduced by the loss of the shared edge in the score calculation. For models in an M_SHAPE_CIRCLE type of Model Finder context, M_SHARED_EDGES is not supported.
Fit error weighting factor
The fit error weighting factor, MmodControl() with M_FIT_ERROR_WEIGHTING_FACTOR, determines the relative importance of the fit error when calculating the match score and the target score. The higher the factor, the greater the influence that the fit error has on the resulting score and target score for an occurrence (see the Determining what is a match section earlier in this chapter). Setting this factor to 0.0 means that the fit error is not considered in the score calculation, so the score is equal to the coverage score. Setting this factor to 100.0 means that the fit error has a maximum contribution in the score. The default value for M_FIT_ERROR_WEIGHTING_FACTOR is 25.0%.