Rules for character placement
- See also

 Availability
Availability
 Previous
Previous
- Next

-
A digit (M_DIGIT): '0' to '9'.
-
A letter (M_LETTER): 'a' to 'z' and 'A' to 'Z'.
-
An uppercase letter (M_LETTER + M_UPPERCASE): 'A' to 'Z'.
-
A lowercase letter (M_LETTER + M_LOWERCASE): 'a' to 'z'.
-
A combination of the above types (for example, M_DIGIT + M_LETTER).
-
Any character (M_ANY).
The read operation (MstrRead()) compares each character in the target image to each character in the font and locates the best string that satisfies all your constraints. You can place constraints on the size of the string, and on the characters themselves. Used together, these constraints form the grammar rules. By setting up proper grammar rules, you can restrict the character comparison process, thereby increasing the robustness of the read operation, and lowering the possibility of false positive results.
Every grammar rule that you set for a string model is referred to as the string model's grammar, while every grammar rule that you set for all string models in the String Reader context is referred to as the context's grammar. Note that you do not explicitly set grammar rules for the context. The context's grammar is formed by all the grammar rules for all the string models within that context.
The space character cannot be set as a constraint and is not counted in the string size. For more information, see the Space section earlier in this chapter.
String size
String Reader will read the number of characters specified by the string size. For best results, the number of characters to be read in your target image should match your string size.
You can set the maximum and minimum number of characters a string must have for it to be read using M_STRING_SIZE_MAX and M_STRING_SIZE_MIN. You can set these to any value greater than or equal to 1. The maximum string size can also be set to infinite (M_INFINITE).
Note that if your strings are very short (a single character in length), MstrRead() might not be as robust.
Character constraints
To ensure that only a certain type of character (or a particular character) appears at a specific position in the string, you can apply character constraints, using MstrSetConstraint(). You can specify that a character at a specific position falls into one of the following types of characters:
For example, if you set the character constraint for the character at position 1 to M_DIGIT, then only if the character at position 1 is between '0' and '9' can it be considered part of the string.
You can further restrict the character constraint to a specific list of characters of the specified type. This list can include special characters and punctuations (for example, 'a', '1', 'aA1', '&', '-', '...'). For example, if you set the character constraint for the character at position 1 to '1', then only if the character at position 1 is '1' can it be considered part of the string.
When providing a specific list of characters, you must ensure that the characters are of the correct constraint type. For example, if the specific character in the list is '1', and the constraint type is M_LETTER, an error will be generated. Also, you cannot repeat letters in your character list; that is, each letter must be unique. For example, 'AABB' is not allowed.
Note that a constraint can be set for any position, even when the string to read does not contain a character at that position. For example, you can set a constraint for a position that is greater than the number of characters in the string. Such constraints are always ignored.
How constraints are used with string models and fonts
You can apply the constraint to a specific string model in the context, or to all string models in the context, using M_STRING_INDEX().
If it is appropriate, you can set a default (M_DEFAULT) constraint for the string model. This constraint will be used for any character in the string for which a constraint has not been explicitly set. This is useful if the majority of the characters must respect the same constraint. For example, you can have an application that reads 26 characters, all of which are digits, except for the character at position three, which is a letter. Rather than having 26 lines of code with almost identical MstrSetConstraint() calls (one for each character position), you can simplify your code by:
The constraint is automatically used with any font in the context. To restrict the constraint to a specific font, set M_FONT_INDEX() to the index value of a specific font, and add it to the constraint (for example, M_DIGIT + M_FONT_INDEX()). This allows you to, for example, write an ANPR application that reads old and new license plates that use different fonts. Your application can specify an "OldPlates" string model with Font1 and a "NewPlates" string model with Font2.
Note that the specified font index can be for a font that does not currently exist. However, if the font still does not exist at preprocessing time, an error will be generated. At preprocessing time, each character in an explicit character list constraint must exist in at least one of the fonts, otherwise an error will be generated.
Grammar rules
Grammar rules refer to both character constraints and string size constraints, which are typically used together in concert. For example, you have an application that reads name tags. Your grammar rules specify that the minimum string size is set to 6 and the maximum string size is set to 12. Your grammar rules also specify the following character constraints for each of your string's 12 positions:
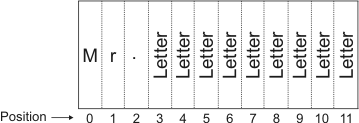
In this case, the following table lists some strings that would be either accepted or rejected for the read operation:
|
String |
Read state |
|
Mr. White |
Accepted |
|
Mr. Orange |
Accepted |
|
Mr. Blonde |
Accepted |
|
Mr. Pink |
Accepted |
|
Joe Cabot |
Rejected |
|
Mr. Lawrence Bender |
Rejected |
|
Mr. X |
Rejected |
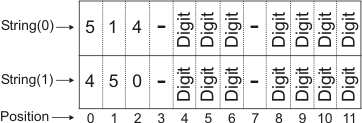
As previously mentioned, each string model in a String Reader context can have a different set of grammar rules. This gives the String Reader module a lot of versatility; it allows you to read many different types of strings within a single context. For example, you want to read two types of telephone numbers, one that starts with '514', and another that starts with '450'. You can therefore create two string models, one for each area code. In this case, the grammar rules for both string models would be exactly the same, except for the constraint placed on the first three characters:
The advantage of having grammar rules can also be seen when writing an ANPR application. For example, the majority of Quebec license plates have two types of strings: three letters followed by three digits, or three digits followed by three letters.

If you want to write an application that reads these license plates, you would need two string models. Each would have a maximum and minimum size of 6. One model would read letter, letter, letter, digit, digit, digit, and another model would read digit, digit, digit, letter, letter, letter.
Note that, if you developed such an application using the OCR module instead of the String Reader module, it would be more complex to write, and less able to reject incorrect strings. Since the OCR module does not allow for grammar rules, the state of all characters cannot be inferred by the state of some. For example, you know that for Quebec license plates, strings that start with a digit must have three digits followed by three letters. Similarly, strings that start with a letter must have three letters followed by three digits. While String Reader can make this assumption, OCR cannot. With OCR, you would have to specify, for each character position, digit or letter. Although this would read the license plates, it might also read some strings that are not license plates (false positives). That is, if the character at position 0 is a letter, it is simply not true that the character at position 1 can be either a letter or a digit; it must be a letter. Having the ability to apply grammar rules helps you avoid such inaccuracies.