Degrees of freedom
By default, the String Reader module has been configured to conduct a fast and robust read operation, with a reasonable degree of tolerance for potential strings in the target image. However, to read unusually sized and positioned strings, you might have to change the tolerance defaults. Specifically, you might have to modify the default angle, scale, aspect ratio, baseline, and skew settings with which the strings are read. Increasing these tolerances can increase the time of the read operation.
Tolerance values are always relative to applicable angle, scale, aspect ratio, and baseline values that you have set. For example, the baseline's tolerance depends on the size of the character; therefore, if a character has been scaled, the tolerance is calculated at that scale.
String angle and character angle
The angle of the string is the angle of the best-fit line that falls on the baseline of all the characters in that string. For example, the angle of the following string is -10°:

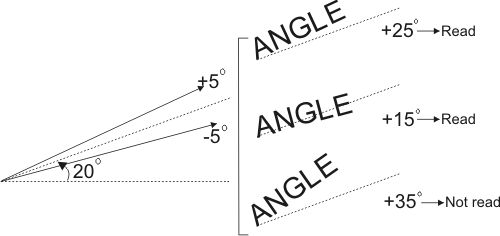
By default, if the target image buffer has no region of interest (ROI), the String Reader module can read strings in the target image at a nominal angle of 0.0°, and with an angular tolerance of +/- 10.0°. This means that only those strings in the target image that have an angle between +10.0° and -10.0° can actually be retrieved as results. For a target image buffer with an ROI, String Reader assumes that the nominal angle of the string is the same as the angle of the ROI, with an angular tolerance of +/- 10.0°; String Reader only supports a rectangular ROI. To set (or re-set) the ROI of the target image, you must create a rectangular graphic element, using the Graphics module, that corresponds to the region and angle of the target string in the target image, and use this graphic element when calling MbufSetRegion().
To change the angular tolerance, use MstrControl() with M_STRING_ANGLE_DELTA_POS and M_STRING_ANGLE_DELTA_NEG. Valid values are between 0.0° and 10.0°. These tolerance values are relative to the nominal angle of the string. Essentially, M_STRING_ANGLE_DELTA_POS and M_STRING_ANGLE_DELTA_NEG set the possible upper (clockwise) and lower (counter-clockwise) limits of the string's angular range (relative to the nominal angle of the string). The upper limit can be described as the nominal angle + M_STRING_ANGLE_DELTA_POS, while the lower limit can be described as the nominal angle - M_STRING_ANGLE_DELTA_NEG. Strings with angles outside this angular range will not be returned as results.
For example, if you know that a string in the target image will typically be located at 20.0°, but you want to allow for an angular tolerance of +/- 5° (a range of 15° to 25°), you should set M_STRING_ANGLE_DELTA_NEG and M_STRING_ANGLE_DELTA_POS to 5.0°, and set (or re-set) the ROI of the target image to 20.0°.
Each character within the string also has an angle. Typically, this angle value is the same as the string's angle value; however, this is not mandatory. The following example illustrates the difference between a string angle and a character angle; the characters in the string have an angle of 10°, while the angle of the string itself is 0°.

To retrieve the string angle, use MstrGetResult() with M_STRING_ANGLE. To retrieve the character angle of the string, use MstrGetResult() with M_CHAR_ANGLE.
Note that the String Reader algorithm is naturally robust to variations in a character's angle. However, if you expect your characters to be located between a wide angular range, it is recommended to enable calculations specific to angular-range search strategies. To do so, use MstrControl() with M_SEARCH_CHAR_ANGLE. Enabling this setting might increase the read operation's processing time.
String scale and character scale
The scale of the string is the median scale, in the X-direction, of each individual character in that string. By default, strings are located in the target image at a nominal scale of 1.0, with a maximum permitted scale of 2.0 and a minimum permitted scale of 0.5. This means that strings in the target image that have a scale between 0.5 and 2.0 can be returned as results.
By default, the scale of each individual character within the string can vary from the scale of the string by a maximum factor of 1.1 and a minimum factor of 0.9. This means that characters that have a scale between 1.1 and 0.9 (from the string scale) can be considered part of the string.
To alter the maximum (upper limit) and minimum (lower limit) permitted string and character scales, use MstrControl() with M_STRING_SCALE_MAX_FACTOR, M_STRING_SCALE_MIN_FACTOR, M_CHAR_SCALE_MAX_FACTOR, and M_CHAR_SCALE_MIN_FACTOR. Valid values for the maximum string and character scales are between 1.0 and 2.0. Valid values for the minimum string and character scales are between 0.5 and 1.0. String scales are relative to the nominal scale of the string, that is, M_STRING_SCALE x M_STRING_SCALE_MAX_FACTOR or M_STRING_SCALE_MIN_FACTOR. You can set M_STRING_SCALE with MstrControl(). Valid string scale values are between 0.25 and 4.0. Character scales are relative to the scale of the string in the target image, as calculated by String Reader. That is, CalculatedStringScale x M_CHAR_SCALE_MAX_FACTOR or M_CHAR_SCALE_MIN_FACTOR. Note that M_CHAR_SCALE_MAX_FACTOR and M_CHAR_SCALE_MIN_FACTOR define how much an individual character's scale can deviate from the string's scale.
For example, you want to write an application that reads the string 'ABCD' within a scale range of 0.5 to 2.0. However, you want to ensure that the scale of each individual character in the string only ranges between 0.9 and 1.1. To do so, set M_STRING_SCALE to 1.0, M_STRING_SCALE_MAX_FACTOR and M_STRING_SCALE_MIN_FACTOR to 2.0 and 0.5, and M_CHAR_SCALE_MAX_FACTOR and M_CHAR_SCALE_MIN_FACTOR to 1.1 and 0.9.
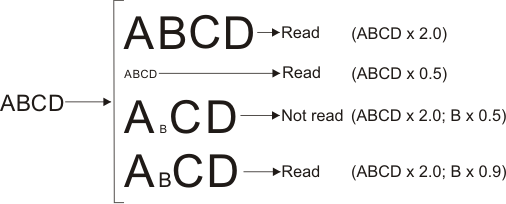
To retrieve the string scale, use MstrGetResult() with M_STRING_SCALE. To retrieve the character scale, use MstrGetResult() with M_CHAR_SCALE. Strings and characters with scales outside their respective range will not be returned as results. Note that characters that are outside the string's upper and lower limits will not be read.
String aspect ratio and character aspect ratio
The aspect ratio of a string is the median aspect ratio of each individual character in that string. The aspect ratio of a character is the ratio of its scale in the X-direction by its scale in the Y-direction. By default, strings are located in the target image at a nominal aspect ratio of 1.0, with a maximum permitted aspect ratio of 1.25 and a minimum permitted aspect ratio of 0.8. This means that strings in the target image that have an aspect ratio between 1.25 and 0.8 can be returned as results.
By default, the aspect ratio of each individual character within the string can vary from the aspect ratio of the string by a maximum factor of 1.1, and a minimum factor of 0.9. This means that only characters that have an aspect ratio between 1.1 and 0.9 (from the string aspect ratio) can be considered part of the string.
To alter the maximum (upper limit) and minimum (lower limit) permitted string and character aspect ratios, use MstrControl() with M_STRING_ASPECT_RATIO_MAX_FACTOR, M_STRING_ASPECT_RATIO_MIN_FACTOR, M_CHAR_ASPECT_RATIO_MAX_FACTOR, and M_CHAR_ASPECT_RATIO_MIN_FACTOR. Valid values for the maximum string and character aspect ratios are between 1.0 and 2.0. Valid values for the minimum string and character aspect ratios are between 0.5 and 1.0. String aspect ratios are relative to the nominal aspect ratio of the string, that is, M_STRING_ASPECT_RATIO x M_STRING_ASPECT_RATIO_MAX_FACTOR or M_STRING_ASPECT_RATIO_MIN_FACTOR. You can set M_STRING_ASPECT_RATIO with MstrControl(). Valid string aspect ratios are between 0.5 to 2.0. Character aspect ratios are relative to the aspect ratio of the string in the target image, as calculated by String Reader. That is, CalculatedStringAspectRatio x M_CHAR_ASPECT_RATIO_MAX_FACTOR or M_CHAR_ASPECT_RATIO_MIN_FACTOR. Note that M_CHAR_ASPECT_RATIO_MAX_FACTOR and M_CHAR_ASPECT_RATIO_MIN_FACTOR define how much an individual character's aspect ratio can deviate from the string's aspect ratio.
For example, you want to write an application that reads the string 'ABCD' within an aspect ratio range of 0.5 to 2.0. However, you want to ensure that the aspect ratio of each individual character in the string only ranges between 0.9 and 1.1. To do so, set M_STRING_ASPECT_RATIO to 1.0, M_STRING_ASPECT_RATIO_MAX_FACTOR and M_STRING_ASPECT_RATIO_MIN_FACTOR to 2.0 and 0.5, and M_CHAR_ASPECT_RATIO_MAX_FACTOR and M_CHAR_ASPECT_RATIO_MIN_FACTOR to 1.1 and 0.9.
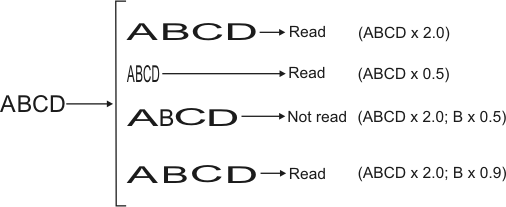
To retrieve the string aspect ratio, use MstrGetResult() with M_STRING_ASPECT_RATIO. To retrieve the character aspect ratio, use MstrGetResult() with M_CHAR_ASPECT_RATIO. Strings and characters with aspect ratios outside their respective range will not be returned as results. Note that characters that are outside the string's upper and lower limits will not be read.
Character's maximum baseline deviation
In a target image, most characters in a string do not rest on significantly different baselines. However, you might encounter a target image where certain characters are significantly misaligned. In some cases, these strings are valid and you want to be able to read them. For example, when dealing with odometers, certain digits might be considerably misaligned with the other digits, yet the string is still valid, such as in the following image:

The image above shows that '6' has a baseline deviation. A character's baseline deviation is the difference between the character's baseline and the baseline of the string in which it is found. A character's maximum baseline deviation is the maximum tolerable baseline deviation that a character in a string can have before it is rejected from the string. In most cases, a character's baseline deviation is calculated as a percentage of the character's height. For the example above, a baseline deviation of 15 for '6' means that 6's baseline deviates from the string's baseline by 15% of 6's height. However, for punctuation characters, the baseline deviation is calculated as a percentage of the height of the character with the largest Y-size in the font.
By default, all characters are assigned a default maximum baseline deviation of 10. This value is a sufficient tolerance for most applications because characters in a string in a target image do not usually rest on significantly different baselines. However, in certain situations such as the odometer case, the default value might not be sufficient for the String Reader to accept the misaligned character. If the misaligned character's baseline deviation is more than the character's set maximum baseline deviation, the character will be rejected from the string. This is why in some cases, you must manually change the characters' maximum baseline deviation.
To set the maximum baseline deviation that all characters in the string can have, use MstrControl() with M_CHAR_MAX_BASELINE_DEVIATION. Valid values are between 0 and 100. The default value is 10.
To retrieve every read character's baseline deviation, use MstrGetResult() with M_CHAR_BASELINE_DEVIATION.
Consider now the target image shown below. Let us assume that in the font, 'p' had its baseline defined as 26.7%, which is illustrated by the dotted line (for more information on baselines, see the Baseline subsection of the Creating and customizing the fonts for a font-based context section earlier in this chapter). We can see that in the target image, 'p' is misaligned with the other characters, and therefore there is a baseline deviation. If this baseline deviation is larger than the set maximum baseline deviation, the character will be rejected from the string. If this is the case and you want the String Reader to accept 'p', you need to increase the characters' maximum baseline deviation.
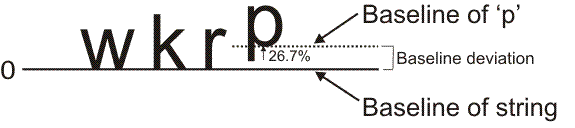
As mentioned previously, the baseline deviation for punctuation characters is represented as a percentage of the height of the character with the largest Y-size in the font. This is used because the Y-size of punctuation characters is typically too small to calculate baseline deviation as a percentage of the character's height. The image below shows the string, 'wkrp-'. Suppose the hyphen's baseline was defined in the font as -250%. The target image shown has the hyphen's baseline misaligned from the other characters' baseline; therefore, there is a baseline deviation. Let us assume that 'k' is the character with the largest Y-size in the font. To calculate the baseline deviation, instead of using the height of the hyphen, String Reader uses 'k' to measure the baseline deviation. From the right side of the image below, you can see that the baseline deviation of the hyphen corresponds to 30% of k's height. If 30 is larger than the set maximum baseline deviation, the hyphen will be rejected from the string. In this case, to accept '-', you need to increase the characters' maximum baseline deviation.

Note that a character's baseline deviation is represented at the scale of the target image. With non-punctuation characters, the baseline deviation is represented as a percentage of the character's height at the scale of the target image. With punctuation characters, the baseline deviation is represented as a percentage of the character with the greatest Y-size within the font, but at the scale of the string in the target image.
Skew angle
The term skew can be defined as a rotational deviation from the correct horizontal and vertical orientation. Typically, when dealing with characters, a skew presents itself as a lateral or horizontal lean.

The String Reader algorithm is naturally robust to variations in a character's skew angle. However, if you expect your characters to be skewed with a wide angular range (for example, when dealing with significant shifts in perspective), it is recommended to enable calculations specific to angular-range skew search strategies. To do so, use MstrControl() with M_SEARCH_SKEW_ANGLE. Note that enabling this setting might increase the read operation's processing time.
The skew angle for each character within a string must always be the same. To retrieve the character's skew angle, use MstrGetResult() with M_SKEW_ANGLE.