Training: analyze and adjust
- See also

 Availability
Availability
 Previous
Previous
- Next

-
The classifier over-fitting the training data, which usually means the classifier is not general enough to perform properly in the field (during prediction).
-
Improperly augmented data, which can cause the classifier to learn how to solve a problem other than the one that was originally presented.
-
Minimum accuracy.
-
Minimum false positive and false negative rates.
-
Minimum advanced error metrics.
-
Execution speed on the target platform (CPU).
-
The loss value, which is updated after each epoch, generally decreases on average.
-
The accuracy of the training and development datasets, after each epoch, generally increases on average.
-
The proper evolution of loss:
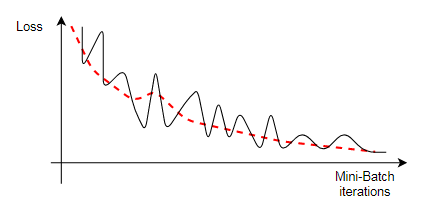
-
Under-fitting symptoms:
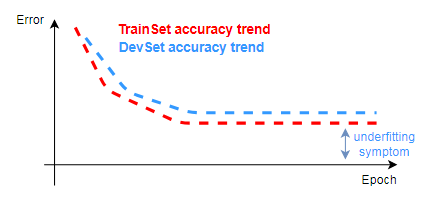
-
Over-fitting symptoms:
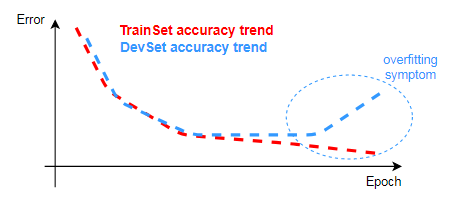
-
Train longer by increasing the maximum number of epochs.
-
Use a predefined CNN classifier with a larger capacity. Smaller classifiers can fail to handle complex problem.
-
Try to use inputs (for example, images) with more features, such as color. A lack of features can hinder robust classifications.
-
Adjust training mode related settings (hyperparameters), such as increasing the initial learning rate.
-
Collect and label more data to increase the training dataset.
You can also add augmented data to the training dataset to regularize the training process.
-
Adjust training mode related settings (hyperparameters), such as increasing the initial learning rate.
Ideally, after you set up your training settings, call MclassTrain(), and review your training results, you realize that your classifier is perfectly trained and you can use it with MclassPredict().
However training traditionally takes a substantial amount of time. Although this time includes analyzing training results, modifying training settings, and recalling the training function, it also includes the execution of the training function itself, and how it might be training incorrectly. In such cases, you can end up waiting a long time for the training to complete, only to find out that the training is completely wrong. This can be caused by several factors, such as inappropriate architecture, hyperparameters, and datasets.
For example, a very small initial learning rate (such as, 10^-6) can make a complete training process extremely slow. To help mitigate this, you can call two hook functions (also known as callbacks), one at the end of each mini-batch, and a second at the end of each epoch.
This hooking mechanism helps ensure that training is developing in the correct direction, while it is happening. Specifically, you can use MclassHookFunction() to hook a function to a training event, and then call MclassGetHookInfo() to get information about the event that caused the hook-handler function to be called.
Hooking lets you retrieve critical training information, such as the current loss value, training dataset accuracy, and development dataset accuracy. Collecting this information helps you analyze the success of the training and to assess the classifier's performance. The training process can also be interrupted while in the hook (callback) function.
Inherently, training can take a lot of time; you should therefore typically expect to monitor the training process for proper convergence, and to make modifications to the process, or even to abort and restart it, if required. Proper convergence refers to increasing accuracy and minimizing error; in this way, you are converging to a classifier that properly identifies the class to which the data belongs.
Results
To retrieve training results, call MclassGetResult() with the training result buffer that MclassTrain() produced.
You will often get results related to accuracy, such as the accuracy of the training dataset (M_TRAIN_DATASET_ACCURACY), the development dataset (M_DEV_DATASET_ACCURACY), and the out-of-bag set (M_OUT_OF_BAG_ACCURACY), the latter being exclusively for tree ensemble.
Typically, you are not only interested in the accuracy of the classifier, but also in the robustness of that accuracy. A properly trained classifier has both a high accuracy (or, conversely, a low error or loss), and has also been trained in such a way that, if given similar input that it has not seen, will continue to behave as accurately as you expect. As discussed in the following sections, recognizing a properly trained classifier can sometimes be tricky business.
Recognizing a properly trained classifier
A properly trained classifier is ready for prediction. But what does properly trained mean?
A properly trained classifier captures the general problem and successfully generalizes it so that it has a good accuracy on the trained data, and also on future data that is similar. This generalization requirement represents the main reason to organize data in separate datasets (for example, the training dataset and the development dataset); you must ensure that the classifier does not under-fit, nor over-fit, the problem.
Typical issues to suggest that a classifier is not properly trained include:
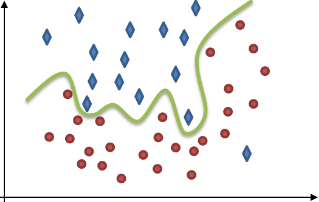
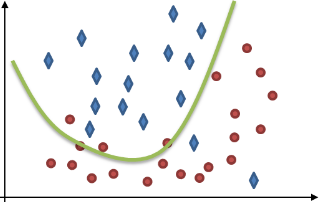
The following images illustrate two kinds of data represented by diamonds and circles, and the kinds of issues a classifier might have trying to differentiate between them. This differentiation, which is also known as the classifier's solution or data split, is indicated by a green line.
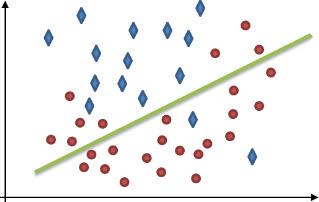
|
|
|
|
The classifier separates the data badly, given the numerous errors. Do not consider this classifier properly trained; its solution is too general as it under-fits the problem. |
The classifier perfectly separates every detail of data and disregards any underlying trend. This solution is unlikely to work on new data (prediction). Do not consider this classifier properly trained; it is not general enough as it over-fits the problem. |
The classifier almost perfectly separates the data by capturing an underlying trend. You should consider this classifier properly trained; it has effectively generalized a solution. |
A properly trained classifier might also have to meet the following requirements:
As previously discussed, MIL uses the development dataset, which is required for training a CNN, to help regulate training issues such as overfitting (to a certain degree, tree ensemble classifiers use bagging for this). Nevertheless, such issues can still occur and might be a sign that there is an underlying problem with how the training data is represented as a whole (and not how it was split).
Expected trends and fluctuations
Despite fluctuating values, you should expect the following while the training is occurring:
These overall trends indicate that training is proceeding successfully. The amplitude of the fluctuations typically decreases with larger batch sizes. The loss value decreases very fast over the first iterations, thus a logarithmic scale is commonly used to display the loss so you can observe its long-term evolution.
After many epochs, if the error rates reach steady states and their values are far from expectations, the training process can be canceled before it ends, by calling MclassControl() with M_STOP_TRAIN.
Examination
At the end of the training, the overall evolution of the error rate and the loss is the first area of analysis.
The error trends of both the training dataset and the development dataset should decrease over time. Given enough time (a large number of epochs), the training dataset error should eventually reach a minimum, and the classifier should perform as well as the expert in the domain.
The development dataset error is also expected to decrease to a minimum, but the error might be unacceptably greater than the training dataset error. Also, if at some point in time, the development dataset error, after reaching a minimum, starts increasing (gets worse), the classifier is probably over-fitting the data.
These are some examples of typical results you can get after training.
The following graphs show a proper evolution of the error rate (the graph on the left) and the loss (the graph on the right) of the training dataset (in green) and the development dataset (in purple) during the execution of MclassTrain(). The error rate eventually converges to 0% and the loss gets down to 0.0015872. Note, the error rate can be seen as a kind of compliment to accuracy; the lower the error, the higher you can consider the accuracy.
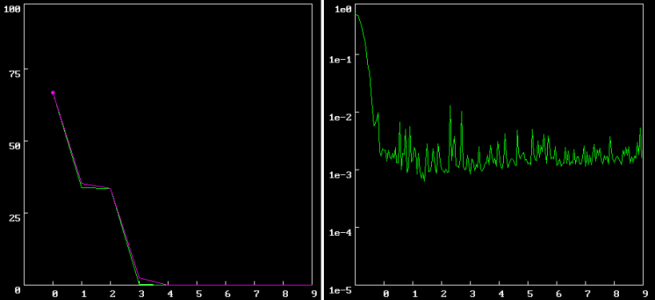
You should abort the training process if the values level off prematurely or at an unacceptable level.
Adjustments
Observing issues in training, such as over- or under-fitting, is known as bias and variance analysis. This is done so you can understand how your classifier was trained and figure out the adjustments you can make so you can retrain in a better way.
Bias and variance analysis
The bias and variance analysis is typically based on observing errors related to the training dataset and development dataset. This analysis can help guide what you should adjust to improve the training when you recall MclassTrain().
The following image summarize the issues and what you can do; the subsequent subsections elaborates on this.
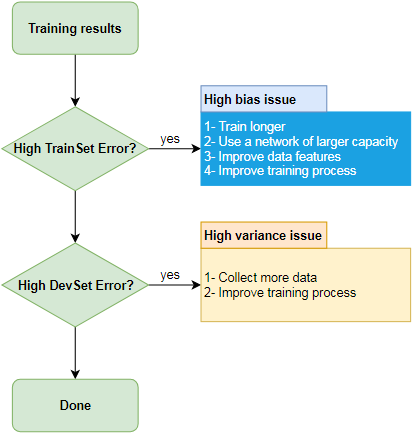
High training dataset error
The training dataset error measures the number of miss-classified training dataset entries relative to the total number of training dataset entries. Ideally, the training dataset error converges to the Bayes error rate, which is the lowest possible error for any classifier.
Typically, human and Bayes errors are close, and it is expected that the difference between the training dataset error and the human error, the avoidable bias, can be reduced to its minimum. A high training dataset error often indicates that the classifier is under-fit.
Given no major mislabeling error in the dataset, such as a systematic labeling error, if the training dataset error is high, try taking the following bias reduction actions:
High development dataset error
The development dataset error measures the number of miss-classified development dataset entries relative to the total number of development dataset entries. Ideally, the development dataset error should converge as close as possible to the training dataset error.
A high development dataset error often indicates that the classifier is over-fit.
Given no major mislabeling error in the dataset, such as a systematic labeling error, if the development dataset error is high, try taking the following variance reduction actions:
Note, investigating the development dataset errors together with the training dataset errors helps determine if the classifier was trained more than it should have been.
Beware of useless pursuits
On occasion, despite repeatedly training and adjusting and retraining, it can seem impossible to draw any more improvements from your classifier. Some of the most difficult cases can occur when your classifier is able to split your data to a fairly good degree, but has stubbornly plateaued at a level that just isn't good enough.
In these cases, you should try implementing more advanced techniques and examinations, such as analyzing the confusion matrix, scrutinizing the score distribution, and having a deployed application intended to collect data that you can then use to improve training and update the application. It is possible that such examinations indicate problems with your data, which could mean improving or restructuring your datasets. For more information, see the Advanced techniques section later in this chapter.