Customizing read and grade operation settings
- See also

 Availability
Availability
 Previous
Previous
- Next

This section provides information to consider and describes settings that you might have to change for McodeRead() or McodeGrade() operation.
You can also train many of these settings using McodeTrain() with a sample set of your images. To establish which can be trained, refer to their description in McodeControl() in the MIL Reference; to increase efficiency when browsing control types, use filters to limit table values to those of that can be trained. For information on training, see the Training read and grade operation settings section earlier in this chapter.
Reading and grading multiple occurrences
The MIL Code module is designed to read and grade one or many code occurrences in an image; the module only supports searching for multiple occurrences of 1D code types (excluding 4-State, GS1 Databar, Planet, and Postnet code types) and the Data Matrix code type. When reading or grading multiple code occurrences, multiple results (one set of results for each occurrence of each code model) can be retrieved using McodeGetResult().
If you want to read/grade more than one code occurrence in the image, set the number of code occurrences to read for each code model using McodeControl() with M_NUMBER. To set the total number of code occurrences to read, use McodeControl() with M_TOTAL_NUMBER; the default value is M_ALL, which finds the expected number of occurrences specified for each code model.
For example, if an application must read one code occurrence in an image, you should add a code model to the code context for each possible code type that the code occurrence can be. Since only one code occurrence must be read for any image, you should set M_TOTAL_NUMBER to 1, and set M_NUMBER for each code model to 1.
The following table further demonstrates the relationship between M_TOTAL_NUMBER and M_NUMBER, by showing an example of different combinations of possible results:
|
Code context element |
Number of occurrences set |
Number of occurrences read or graded |
|||||||
|
Ex. 1 |
Ex. 2 |
Ex. 3 |
Ex. 4 |
Ex. 5 |
Ex. 6 |
Ex. 7 |
Ex. 8 |
||
|
Context |
5 (maximum) |
5 |
5 |
5 |
5 |
5 |
5 |
5 |
5 |
|
Model 0 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
|
Model 1 |
3 |
0 |
0 |
1 |
1 |
2 |
2 |
3 |
3 |
|
Model 2 |
5 |
4 |
4 |
3 |
3 |
2 |
2 |
1 |
|
When reading multiple occurrences, it is recommended to set M_POSITION_ACCURACY to M_HIGH to increase the accuracy of the read.
Child buffers
For McodeRead() and McodeGrade(), It is recommended to use a child buffer, especially if your images contain more code occurrences than your code context is configured to read/grade; otherwise, MIL will select which code occurrences to read/grade, up to the specified maximum number of code occurrences (McodeControl() with M_TOTAL_NUMBER). Using child buffers is also recommended because it allows for a faster and more robust operation if your images contain other information that might be misinterpreted as a code occurrence.
A quiet zone is an optional part of each 1D code type's specification and a required part of each 2D code type's specification (except for Aztec). For best results, if a code occurrence has a quiet zone, your child buffer must be large enough to contain the quiet zone. Generally, the minimum quiet zone for a 1D code type is ten times the width of the smallest bar and space. For a 2D code type, the width is generally a factor of the size of the cell. MIL uses the quiet zone to identify the beginning/end of the code occurrence. MIL can, in some cases, successfully read a code occurrence that does not meet the minimum requirements for the quiet zone; however, it is strongly recommended that code occurrences have adequate quiet zones to perform a robust McodeRead() or McodeGrade() operation and return accurate results.
The extended quiet zone, referred to as the extended area of a code occurrence, is an optional part of the specification for the Aztec, Data Matrix, QR, and Micro QR code types. It is an area 20 times the cell size beyond the quiet zone on all sides. If you are grading code occurrences including their extended area (M_EXTENDED_AREA_REFLECTANCE_CHECK), your child buffer must be large enough to contain their extended area.
Regions of interest
Another way to reduce the amount of processing to be performed on your image is to use an image with region of interest (ROI). Similar to a child buffer, an ROI allows for a fast and robust McodeRead() or McodeGrade() operation.
Only a rectangular M_VECTOR or M_VECTOR_AND_RASTER ROI, will be considered. To create such an ROI, use MbufSetRegion() with the ImageOrGraphicListId parameter set to the MIL identifier of a 2D graphics list, and the Operation parameter set to either M_RASTERIZE, M_RASTERIZE_AND_DISCARD_LIST, or M_NO_RASTERIZE.
Presearching
There are some situations where you cannot create a child buffer or an ROI for your McodeRead() or McodeGrade() operation. For example, when you cannot guarantee that the target is not in the same location each time it is read or graded by your application. In this case, you could use the MIL Code module's presearch algorithm. This helps MIL locate 2D code occurrences in the image prior to the read or grade operation. The presearch algorithm is only supported for 2D code occurrences and is disabled by default for efficiency. To set the presearch option, use McodeControl() with M_USE_PRESEARCH.
Foreground color
Setting the foreground color can improve the results of McodeRead() or McodeGrade(). To set the foreground color, use McodeControl() with M_FOREGROUND_VALUE. The default foreground color is black. In situations where the foreground color might change, set M_FOREGROUND_VALUE to M_FOREGROUND_ANY. Note that this impacts the performance of McodeRead() or McodeGrade().
Setting the search speed
You can specify the speed at which to perform McodeRead() or McodeGrade(); the faster the speed, the less robust the operation. In general, the larger and more clearly defined the code occurrence, the better chance it has of being found at a speed higher than the default speed (M_MEDIUM). Specify the search speed using McodeControl() with M_SPEED. If you are having problems finding the code occurrence, you might want to search at a speed lower than the default.
Timing out your search
In certain cases, McodeRead() or McodeGrade() might take longer than necessary for your purposes. In this event, you have two options to reduce the reading or grading time. You can either specify a maximum decoding time for the operation using McodeControl() with M_TIMEOUT, or you can call McodeControl() with M_STOP_READ to stop the current McodeRead() or McodeGrade() operation when required. For the latter option, the call to McodeControl() must be done from another thread.
Cell size and number
In most cases, you should not have to specify the cell size or number of cells when reading or grading code occurrences; MIL can search for the specified code type and automatically determine the cell size and number of cells within the code occurrence. However, for some 1D code types and 2D code types, such as Data Matrix and Maxicode, McodeRead() or McodeGrade() can perform a more robust operation if you specify the cell size (that is, the size of the cell in X). To increase both the speed and robustness of the operation for 2D code types, you can also specify the number of cells in the X and Y-direction; for M_PDF417, M_TRUNCATED_PDF417, and M_MICROPDF417 code types, instead of specifying the number of cells in the Y-direction, you specify the number of rows.
MIL might have difficulty reading 1D code occurrences if the cell size is less than 2 pixels, and 2D code occurrences if the cell size is less than 3 pixels, even if the size is specified.
You specify the cell size as a range using McodeControl() with M_CELL_SIZE_MIN and M_CELL_SIZE_MAX. MIL will search for code occurrences with cells that fall within this range. If the cell size is not within the specified range, the code occurrence will not be found.
It is highly recommended that you specify the best cell size range possible. This is especially important when using an adaptive threshold, discussed later in the Thresholding subsection of this section. To obtain the best results from a presearch when a code occurrence's cell size is less than 6 or greater than 10, you must specify the cell size minimum and maximum.
You specify the number of cells using McodeControl() with M_CELL_NUMBER_X and M_CELL_NUMBER_Y. Note that specifying the number of cells is mostly useful when reading Aztec, PDF417, Truncated PDF417, Data Matrix, and QRCode code types; the Maxicode code type has a fixed number of cells. For the PDF417 code type, M_CELL_NUMBER_X must equal 17c + 35, where c is the number of columns, and 35 represents the number of cells required for the start and stop patterns. For the Truncated PDF417 code type, M_CELL_NUMBER_X must equal 17c + 18, where c is the number of columns, and 18 represents the number of cells required for the start patterns. When used with M_PDF417, M_TRUNCATED_PDF417, and M_MICROPDF417 code types, M_CELL_NUMBER_Y represents the number of rows.
Search angular range
By default, McodeRead() and McodeGrade() read code occurrences if they fall within the angular range of 0±5°. If the code occurrence appears rotated in the image, specify another nominal angle using McodeControl() with M_SEARCH_ANGLE.
If you are uncertain about the code occurrence's exact orientation or you expect a possible deviation of more than ±5° from the nominal angle, increase the angular range relative to M_SEARCH_ANGLE. Set the lower and upper deviations from the nominal angle using McodeControl() with M_SEARCH_ANGLE_DELTA_NEG and M_SEARCH_ANGLE_DELTA_POS. Optionally, set the step by which to increment or decrement through the search angular range, using McodeControl() with M_SEARCH_ANGLE_STEP. If you don't explicitly specify this step, the search angular range algorithm will automatically establish a step. The search angular range algorithm will first search at the specified nominal angle. It will then toggle between incrementing and decrementing from the nominal angle, with each iteration moving further away from the initial search angle by the value of M_SEARCH_ANGLE_STEP (or the automatically established step). The process will continue until either the code occurrence is found, or the search falls outside of the range defined by M_SEARCH_ANGLE - M_SEARCH_ANGLE_DELTA_NEG and M_SEARCH_ANGLE + M_SEARCH_ANGLE_DELTA_POS.
Note that M_SEARCH_ANGLE_STEP, M_SEARCH_ANGLE_DELTA_NEG and M_SEARCH_ANGLE_DELTA_POS are relative to the nominal angle set by M_SEARCH_ANGLE. While the nominal angle is relative to the input coordinate system specified using M_SEARCH_ANGLE_INPUT_UNITS, M_SEARCH_ANGLE_DELTA_NEG and M_SEARCH_ANGLE_DELTA_POS are not affected by the coordinate system used.
For 1D code types, as the angular range increases, the operation speed might decrease. You can sometimes speed up the search by disabling the search angular range algorithm and trying to read the code occurrence at the specified search (nominal) angle. If the code occurrence deviates from the nominal angle by a few degrees, as in the image below, McodeRead() and McodeGrade() can sometimes successfully read the code occurrence without explicitly searching through a range of angles. To disable the search angular range algorithm, call McodeControl() with M_SEARCH_ANGLE_MODE set to M_DISABLE. The angular range does not affect the speed of the operation when searching for 2D code types, and so it is not necessary to disable the search angular range algorithm.

For 1D code types, the Code module will not use the search angular range algorithm if M_SEARCH_ANGLE_DELTA_NEG and M_SEARCH_ANGLE_DELTA_POS both have a value less than or equal to 5°, regardless of M_SEARCH_ANGLE_MODE. In this instance, M_SEARCH_ANGLE_DELTA_NEG and M_SEARCH_ANGLE_DELTA_POS have no effect.
If bearer bars are present and reading a bar code at an unknown angle, M_BEARER_BAR must be enabled. When bearer bars are caused by background (such as at least one side of the bar code has a dark background that touches only one edge of the lines and spaces, then the speed of the read should be reduced (using M_SPEED set to M_VERY_LOW).
When the search speed is set to M_SPEED set to M_VERY_LOW, a more exhaustive search algorithm is enabled that can exceed the specified angle range. In this case, the specified angle range is used as a starting reference for the search instead of as a search restriction.
In some cases, the target code occurrence might be inverted. For 1D code types, use McodeControl() with M_CODE_FLIP set to M_FLIP to have 1D code occurrences read from right-to-left (as opposed to the standard left-to-right), before trying to read the code occurrence. If you use the setting M_ANY, MIL will decide whether the code occurrence needs to be flipped or not. The default value for M_CODE_FLIP is M_NO_FLIP. If M_CODE_FLIP does not support the code type of a code occurrence that is inverted, you can flip the code occurrence vertically or horizontally using MimFlip().
Dot spacing
Sometimes 2D matrix code occurrences are composed of dots, such as when a code occurrence is punched into an object. In an ideal situation, the cell containing the dot (and its surrounding border of white space) matches the expected cell size for your code type. However, often in these cases, the dots have some spacing between them, which can make the code occurrence more difficult to read. For best results, set the dot spacing using McodeControl() with M_DOT_SPACING_MIN and M_DOT_SPACING_MAX. Set each to a range that covers half the pixel distance between dots. If a 2D code occurrence composed of dots is printed rather than punched, and the cells overlap due to printing artifacts or ink spread, set M_DOT_SPACING_MIN to the minimum negative half the width of the overlap. Set M_DOT_SPACING_MAX to a value greater than M_DOT_SPACING_MIN, but keep the difference between the two relatively small.
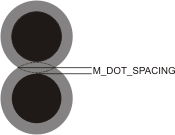
It is recommended to only use a negative dot spacing when the dots are much larger than the expected cell size (typically, when the dots overlap). In the image below, the gray circle represents the actual cell size, while the black dot represents the expected cell size. In this case, specifying a negative dot spacing will assist with future McodeRead() and McodeGrade() operations.
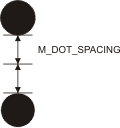
Alternatively, when successive dots are not touching, setting a positive dot spacing will increase the overall size of the cells (that is, the space taken by the dots and the surrounding border of white space for each dot) until they reach the expected cell size. In the image below, there is an abundance of space between the dots. In this case, setting a positive dot spacing equal to half the distance between the dots will assist with future McodeRead() and McodeGrade() operations.
The following is an example of a code occurrence that might need you to specify the dot spacing since its dots are too far apart. By changing the dot spacing better results might be obtained. The image on the right shows how MIL interprets the image after applying positive dot spacing.

If the dots are too close together, specifying a negative dot spacing might result in better results. The image on the right shows how MIL interprets the image after applying negative dot spacing.

String size
You can optionally specify the size of the string encoded in the code occurrence to locate, using McodeControl() with M_STRING_SIZE_MIN and M_STRING_SIZE_MAX.
If you have set M_ERROR_CORRECTION to M_ECC_CHECK_DIGIT, McodeRead() and McodeGrade() assume that there is a check digit at the end of the string. The specified string size should not include the check digit, since the check digit is not returned as part of the string.
The following table lists code types that require a minimum and maximum string size to be specified:
|
Code type |
String size |
|
|
Minimum |
Maximum |
|
|
5, 9, or 11 |
5, 9 or 11 |
|
|
11 or 13 |
11 or 13 |
|
|
3 |
– |
|
|
8 |
8 |
|
|
13 |
13 |
|
|
12 |
12 |
|
Reading EAN 14 code types
Strings encoded with the EAN 14 code type typically start with "(01)", which helps to identify the encoding type of the string. The string can be either 13 or 14 digits in length. Note that the string length should not include "(01)". The optional fourteenth digit is a check digit calculated based on the first 13-digits according to Modulo 10.
Reading GS1-128 code types
Strings encoded with the GS1-128 code type typically start with a two-digit number inside parentheses (for example, (13)). The parentheses surrounding the number will not be read as part of the encoded string, as long as the number matches one of the valid application identifiers for GS1-128 (UCC/EAN-128). If this number is invalid, the parentheses are read as normal characters.
Distortion
If an Aztec, Data Matrix, or QR code occurrence is distorted, McodeRead() and McodeGrade() might not be able to read it due to distortion. In this case, you can apply a distortion compensation algorithm that increases the robustness of the operation. There are two different algorithms that you can use, depending on the code type and the type of distortion present in the code occurrence.
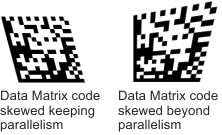
For an Aztec, Data Matrix, or QR code occurrence that has different column widths or row heights, use McodeControl() with M_DECODE_ALGORITHM set to M_CODE_DEFORMED. This algorithm can also work in the presence of perspective distortion. This algorithm can be used for Data Matrix code occurrences that are skewed but still maintain parallelism, and those that are skewed beyond parallelism. When there is noise, damage, or distortion in the finder pattern, you can limit how much deviation to tolerate. Use M_FINDER_PATTERN_MAX_GAP to set the maximum allowable size of a gap (unintended space) in the finder pattern. Use M_FINDER_PATTERN_MINIMUM_LENGTH to set the minimum acceptable length of one of the "arms" of the finder pattern.

In cases where the clock pattern is too noisy but the code occurrence does not have any distortion (or only a very small amount of distortion), try setting M_DECODE_ALGORITHM to M_CODE_NOT_DEFORMED.
The M_CODE_DEFORMED value is only available for Aztec, Data Matrix, and QR code types. For other code types, use the M_CODE_NOT_DEFORMED value.
Note that the use of a distortion compensation algorithm can lead to longer processing times, so it is best to adjust your setup for optimal speed and robustness.
Thresholding
McodeRead() and McodeGrade() internally binarize the source image so as to separate code occurrences from the background. By default, the threshold value is automatically chosen and is suitable in most cases. However, if you think that a different thresholding mode and/or value would result in a better separation (and therefore in a more efficient operation), you can manually adjust these, using McodeControl() with M_THRESHOLD_MODE and M_THRESHOLD_VALUE, respectively. If the lighting is not uniform across the code occurrence (see the image below for an example) and dealing with 2D matrix code types, MicroPDF417, or 1D code types (excluding 4-state, Planet and Postnet), use M_THRESHOLD_MODE with M_ADAPTIVE. This adaptive threshold mode computes, for each pixel, a threshold value based on the pixel's neighborhood.

When dealing with 1D code types (excluding 4-state, Planet, and Postnet) and using adaptive thresholding, you must specify the minimum contrast (McodeControl() with M_MINIMUM_CONTRAST) between the foreground and background in the target image so that McodeRead() and McodeGrade() reads the code occurrence properly. Valid values are between 1 and 255. The default value is 50.
Generally, increasing the minimum contrast will make McodeRead() more robust to non-uniform lighting or noise so that the code occurrence is readable; however, in some instances, it could make a readable code occurrence unreadable. For example, if the contrast between a valid foreground pixel and its background is 25, and you set the minimum contrast to 50, the pixel will not be considered as a foreground pixel. Therefore, it is important to make sure that the minimum contrast value is not causing the operation to ignore code features. In most cases, you can probably estimate an appropriate minimum contrast by looking at your image.
When dealing with 2D code types, the minimum contrast is automatically determined, so the adaptive threshold mode ignores the M_MINIMUM_CONTRAST setting.
Determining whether your code type supports GS1
While some code types have GS1 in their constant names (such as M_GS1_128 and M_GS1_DATABAR), many that can support GS1 do not. It could be instead specified by its subtype and/or its encoding scheme. To determine these values, use McodeInquire() with M_SUB_TYPE and M_ENCODING, respectively. For a listing of encoding and subtypes, see the Supported encoding scheme for composite codes subsection of the Supported encoding schemes, sub-types, and error correction schemes by code type section earlier in this chapter.
The simplest way to determine whether your code type follows the industry standard for a GS1 Databar code (for 1D codes and composite codes) or a GS1 symbology (for 2D codes), use McodeGetResult() with M_IS_GS1. This result type is available for Aztec, Data Matrix, Code 128, EAN-14, GS1-128, GS1-Databar, QR codes, and composite codes.
If M_IS_GS1 returns true, you can set McodeControl() with M_STRING_FORMAT to M_GS1_HUMAN_READABLE to specify that the returned string is human-readable (that is, contains GS1 Application Identifiers or separator strings, in brackets), or M_RAW_DATA to retrieve the string in a raw data format with separator characters.
In the following GS-128 code sample, the raw format returns the following string: è010123456789012815051231. The human-readable version of this string, is returned as follows: (01)01234567890128(15)051231.
