Training: in general
- See also

 Availability
Availability
 Previous
Previous
- Next

-
Allocate a classifier context, using MclassAlloc(). For image classification, specify M_CLASSIFIER_CNN_PREDEFINED. For feature classification, specify M_CLASSIFIER_TREE_ENSEMBLE.
All classification objects must be for the same type of classifier (CNN or tree ensemble).
-
Allocate a training context, using MclassAlloc() with M_TRAIN_CNN or M_TRAIN_TREE_ENSEMBLE. A training context holds the settings with which to train a classifier context.
-
Allocate a classification result buffer to hold training results, using MclassAllocResult() with M_TRAIN_CNN_RESULT or M_TRAIN_TREE_ENSEMBLE_RESULT.
-
Modify training settings, using MclassControl() and MclassControlEntry().
-
Optionally, hook functions to training events, using MclassHookFunction().
-
Preprocess the training context, using MclassPreprocess().
-
Train the classifier context, using MclassTrain().
-
Optionally, get and draw training results, using MclassGetResult() and MclassDraw().
-
Optionally, get information about training events that caused the hook-handler function to execute, using MclassGetHookInfo().
-
Copy the classification result buffer that MclassTrain() produced into a classifier context, using MclassCopyResult(). Once copied, the classifier context is considered trained.
-
If necessary, adjust training settings and contexts, and call MclassTrain() with the trained classifier context.
Training a classifier context requires dataset contexts and a training context. You must specify each of these contexts when you call MclassTrain().
Training time varies considerably, depending on the complexity of the application, the available hardware, and the accuracy required. To produce a properly trained classifier, MclassTrain() might have to run for an extended period, and you might have to call it several times after modifying your training settings. In some cases, you might need to modify your datasets also, and then return to training. Once the training process returns the results you require, you can predict with it.
You do not have much direct control over the classifier context. Your control lies in training the classifier context. That is, you make modifications to the training context (for example, by calling MclassControl()), and then use that training context to affect the classifier context, by calling MclassTrain(). As previously discussed, your datasets vitally affect your classifier's training as well.
Steps to train
The following steps provide a basic methodology for training the classifier context:
You should repeat the training process (train, analyze results, copy results, modify settings, train) until you consider your classifier fully trained and ready for prediction.
Training fundamentals
An untrained classifier context behaves like a random guess; for example, an untrained classifier would have an error rate (or accuracy) of 50% when solving a 2 class (binary) problem.
The goal of training a classifier is to lower its error rate (increase its accuracy) using representative data (datasets) and adjusting training settings. Theoretically (and especially for CNN classifiers), you can see training as an optimization problem that minimizes a cost (or loss) function (minimizes error). If everything is perfect, training results in a classifier that has no loss (no error) and is 100% accurate. Although this is ideal, it is unrealistic when using deep learning or machine learning technologies.
Training is an iterative optimization process; in each iteration, the loss is calculated for all the images in the training set. Then the network's internal parameters (weights) are updated to minimize the loss value (error). For CNNs, each iteration is called an epoch. In each epoch, MIL must load all the data loaded into memory to calculate the loss function and update the weights.
Due to memory limitations, it is typically impossible to load all the data simultaneously, especially when using a CNN classifier, since the data is images (often, thousands of images). To address this, MIL divides this data into small sets called mini-batches. MIL therefore calculates the loss and updates the weights for each mini-batch to minimize that loss. Although training processes each mini-batch independently, the goal is to minimize the global error (the global loss). For tree ensemble classifiers, a somewhat similar process occurs with bootstrapping (bagging).
Keep in mind that if you are training a classifier with a limited amount of data, you can achieve a low error rate (high accuracy) at training time, but get a high error rate (low accuracy) at prediction time. Limited data often causes training to over-fit the classifier on that data; when this happens, the classifier did not generalize the problem and does not perform well when given similar images it has not seen. Limited data can occur when, for example, you need to train with a specific defect, but you do not have many images of that defect because it happens infrequently. For more information about how to recognize a properly trained classifier, see the Training: analyze and adjust section later in this chapter.
Typically, you would perform a training from the ground up; the classifier's internal weights are unset, and totally based on your training settings and data. For CNNs, this is known as a complete training. However, when your data is limited, you might consider using a pretrained CNN classifier as your starting point, if possible. In this case, the pretrained classifier that you are using has already learned to generalize a similar problem to a certain degree, and its internal parameters have been adjusted accordingly. You can therefore build off those adjustments by continuing to train it with your data. This type of CNN training is considered transfer learning. For more information, see the Training modes subsection of the Training: CNN section later in this chapter. Note, training an already trained tree ensemble classifier is considered a warm start.
The following image represents a general overview of what is required to train a CNN classifier. The details in this image will be discussed later in this chapter.
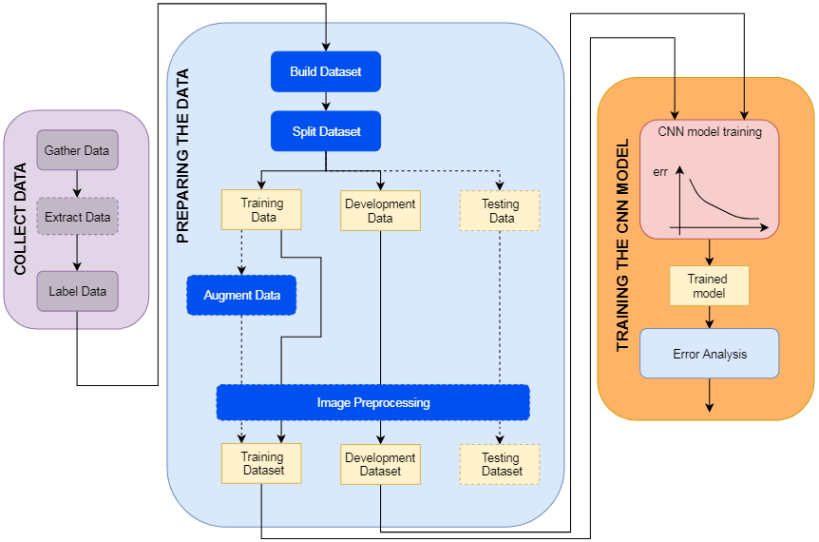
The set of images with which you train the CNN must be representative of the actual application. The images should come from the final imaging setup (for example, the same camera, lens and illumination), and should include the various aspects of the product, as well as its expected variations (for example, changes in scale, rotation, translation, illumination, color, and focus). The size of the images is determined by the application, such as the dimensions of the objects or features to classify, as well as by the specific predefined CNN classifier that you are using.