String models
- See also

 Availability
Availability
 Previous
Previous
- Next

-
Dot diameter.
-
String box dimensions.
-
Minimum and maximum number of characters.
-
Foreground.
-
Intensity and contrast.
-
Acceptance and certainty.
-
Rank.
-
Number of strings to read.
-
String angle.
-
Italic angle.
-
Greater than MinimumSpaceSize and less than MaximumSpaceSize, SureDotOCR considers the characters to be separate characters in the same string, and can insert a space between them. The size of this space is a value between MinimumSpaceSize and MaximumSpaceSize, depending on the actual distance between the characters in the target.
-
Less than MinimumSpaceSize, SureDotOCR considers that there is one character, and will not insert a space character.
-
Greater than MaximumSpaceSize, SureDotOCR considers the characters to be part of separate strings.
-
You cannot represent a space in a font. As discussed, you establish a space with the M_SPACE_SIZE_... context controls.
-
A space constraint is exclusive at a given string model position. For example, if you specify M_SPACE for a position, you cannot add another character constraint, such as M_DIGITS, at that same position.
-
You cannot have a space constraint at consecutive positions in a string model.
-
The first or last position of a string model cannot have a space constraint.
-
Clone the explicit constraints from one position to the next, using M_CLONE_CONSTRAINTS_FROM.
-
Reset the default constraints for the positions in the string model back to their initial value, using M_RESET_IMPLICIT_CONSTRAINTS.
-
Reset the explicitly constrained position to be implicitly constrained, using M_RESET_POSITION_TO_IMPLICIT_CONSTRAINTS.
Once you have explicitly constrained a position, it is considered to be explicitly constrained until you use this operational control, even if you manually set the position's constraints back to the defaults of the string model.
A string model is a data structure, within a SureDotOCR context, that stores the requirements that a dot-matrix string in a target image must meet, for the string to be read. These requirements can range from general to specific; they can apply to the string models themselves, or to the different string model positions. For example, you can create a string model to read any string from a target image that contains any two characters from any font in a context, or you can create a string model to read a string that contains the numbers '4' and '2' from the Galaxy font.
A SureDotOCR context must contain one or more string models. To add a string model to a context, call MdmrControl() with M_STRING_ADD. To delete a string model from a context, use M_STRING_DELETE. You can also call MdmrControl() to control context settings related to string models. To inquire about such settings, call MdmrInquire(). To control and inquire about string models themselves, call MdmrControlStringModel() and MdmrInquireStringModel(), respectively. Context settings related to string models apply to all string models in that context.
For string model modifications to take effect, you must preprocess the context by calling MdmrPreprocess().
Required settings
Before reading dot-matrix text from a target image with MdmrRead(), you must specify the following settings related to string models:
Ideally, the string in the target image should adhere to each of these settings. If it doesn't, the string might still be read, although possibly with a lower resulting score. For more information, see the Acceptance and certainty subsection of this section.
Dot diameter
The dot diameter refers to the size of the dots that represent the characters of the strings in the target.

To set the diameter, call MdmrControl() with M_DOT_DIAMETER. The diameter is set for a context and applies to every dot in all strings read for each string model in that context.
The dots that make up the characters in the image must be visually distinguishable, both vertically and horizontally. If dots are merged into a solid bar, as seen in the following image, there can be difficulties reading.

When dots are merged (that is, you cannot perceive the bump of each dot) due to low resolution or poor focus, improve the image's quality. If a string's characters are printed such that their center to center spacing is less than the dot diameter, it might not be feasible to read such strings reliably.
String box dimensions
The string box refers to a rectangle that encloses all strings to read in a target image.

To set the string box dimensions, call MdmrControl() with M_STRING_BOX_WIDTH and M_STRING_BOX_HEIGHT. According to the angle at which the string is read, the width is oriented along the axis that represents the string's base; while the height is oriented along the vertical axis that is perpendicular to the string's base.
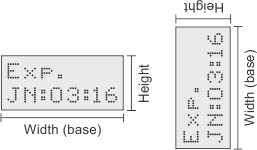
The string box dimensions are set for a context and must enclose all strings to read for all string models in that context. SureDotOCR establishes the center of the string box automatically. The string box should be smaller than the rectangular region of interest (MbufSetRegion()), if the target image specified with MdmrRead() has one.
Maximum and minimum number of characters
The number of characters refers to the size of the string to read in the target.

To set the number of characters, call MdmrControlStringModel() with M_STRING_SIZE_MIN_MAX.
Each character in a string that you expect to read represents a position in the string model. For information about how to constrain the different positions to limit the characters permitted, see the Constraining string model positions with permitted characters subsection of this section.
Optional settings
To fine tune how SureDotOCR reads dot-matrix text from a target image, you can specify the following settings related to string models:
Foreground
Foreground refers to whether the dots that represent the characters of the strings in the target are darker or lighter than the background.

By default, SureDotOCR assumes characters are darker than the backgrounds (for example, black dots on a white surface). To modify this, call MdmrControl() with M_FOREGROUND_VALUE. The foreground is set for a context and applies to all strings read for each string model in that context.
Intensity and contrast
Intensity refers to the average grayscale value of the pixels that make up the character's dots (foreground) in the strings. Since target images must be 8-bit, the highest possible intensity of a dot is 255 (white). The lowest possible intensity is 0 (black).

Contrast refers to the difference in pixel intensity between a character and its background. The greater the difference, the higher the contrast. The following dot-matrix strings, from left to right, show a decrease in contrast.

If a valid character exists in the target image, it can typically be read with the default intensity and contrast settings. However, if the read operation is proving problematic, or you want to try and speed up the read time, you can adjust these settings.
To modify the intensity requirements, set M_MIN_INTENSITY_MODE or M_MAX_INTENSITY_MODE to M_USER_DEFINED. You can then specify a minimum or maximum intensity value with M_MIN_INTENSITY or M_MAX_INTENSITY, respectively. Valid values are between 0 and 255, inclusive. The default minimum is 0; the default maximum is 255.
To modify the contrast requirements, set M_MIN_CONTRAST_MODE to M_USER_DEFINED, and specify a minimum contrast value with M_MIN_CONTRAST. Valid values are between 0 and 255, inclusive. The default value is 15. The default contrast mode is M_AUTO, which automatically establishes the minimum contrast. Note that with M_AUTO, SureDotOCR will not read characters with a contrast less than 15.
SureDotOCR ignores potential character data in the target image that does not have an intensity that falls within the specified min and max range or that does not have a contrast greater than or equal to the specified minimum value. Although this can be useful to fine tune your results and potentially decrease read time, particularly in the presence of noise and in unusually contrasted images, be aware that improperly ignoring image data can cause SureDotOCR to ignore actual characters. Intensity and contrast are set for a context and apply to all strings read for each string model in that context.
Acceptance and certainty
Acceptance and certainty refer to string model settings that regulate when a target string can be read (acceptance) and when a target string must be read (certainty), based on the resulting score of the string and its characters.
When you call MdmrRead(), SureDotOCR analyzes the target image and localizes potential character candidates for each string model. The best candidates that meet the minimum definition of a string (a linear sequence of generally aligned characters) and all user-specified settings will be read.
Every character candidate is given a score between 0 and 100. The higher the score, the better the candidate. This score quantifies, as a percentage, the similarity between the character in the target string and the corresponding character in the font that the string model uses. The string score is the average score of all the characters in the string. To retrieve these scores, call MdmrGetResult() with M_CHAR_SCORE and M_STRING_SCORE.
By default, the acceptance level for the score of both the string and its characters is 50%. To modify these levels, call MdmrControlStringModel() with M_STRING_ACCEPTANCE or M_CHAR_ACCEPTANCE.
Strings can only be read if the string score, and the score of every character, is greater than or equal to their respective acceptance level. For example, if a string has three characters, and the first two have a score of 55%, and the last has a score of 40%, the string's score is 50%, which meets the string's default acceptance level. However, since one character does not meet the default character acceptance level, this string will not be read. To read this string, you can lower the character's acceptance level to 40%, without having to lower the acceptance level of the string.
By default, the certainty level is 70%. If a string's score is equal to or above this level, the string is immediately read as a valid string result, without processing the rest of the target image for strings with higher scores (provided the specified number of strings to read has been read). To modify the certainty level, call MdmrControlStringModel() with M_STRING_CERTAINTY.
Acceptance and certainty are set for string models; each one can have their own levels. You should typically set the acceptance to represent a threshold for a score that is adequate, though you would like to check the rest of the image for strings with better scores. The certainty level represents a threshold for a score that is so amazingly good, you need not even consider the possibility that there is a better string out there. Since lowering the certainty usually results in less image analysis, it can speed up the read operation. Remember to set the certainty carefully, since a low level can cause a premature termination of the read operation, and allow the best candidates to remain unread.
The default acceptance and certainty settings are generally fine. However if you are not getting the results you want, try experimenting with them. For example, changing the acceptance might be necessary for images with poorly printed characters. When used in concert, these settings offer a simple, fast, and versatile way of accepting and rejecting strings.
Rank
Rank refers to the order to read for a string model, relative to the other string models in a context.
SureDotOCR reads strings from left to right, and from top to bottom, with respect to the angle of the target. Following this order, the strings read in the illustrations below are "JOHN", "PAUL", "GEORGE", and "RINGO".
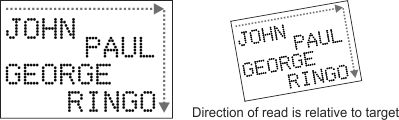
Rank 0 (the default) indicates that the string for that string model should be read first; accounting for angle, it will be the top left-most string. In this example, that first string is "JOHN". Rank is only relevant when there are multiple string models in a context.
To specify a string model's rank, call MdmrControlStringModel() with M_STRING_RANK. String models with lower ranks are read before those with higher ones. Specifying a rank order can make the read operation faster and more accurate. Ranks are set for string models; each one can have its own value. Strings with different ranks must be on separate lines.
If multiple string models have identical ranks, SureDotOCR reads just one string, depending on which is more similar to its string model. For example, if a context has string models with ranks set to [0, 0, 0, 1], only one of the three string models with rank 0 can have a string read for it.
When specifying ranks, you must include rank 0, and you must not skip successive values. For example, if you have four string models with their respective ranks set to [1, 2, 3, 4], you will get an error, because you did not include rank 0. You will also get an error if you set their ranks to [0, 1, 2, 4], because you included ranks 2 and 4 but skipped rank 3. Examples of acceptable rank settings are [0, 1, 2, 3], [0, 0, 0, 0], [2, 2, 1, 0], and [2, 1, 0, 1].
Number of strings to read
SureDotOCR establishes the required number of strings to read for a context according to the rank of its string models (M_STRING_RANK). That is: TotalNumberOfStringsToRead = HighestRankValue + 1. For example, if you have four string models with ranks set to [0, 0, 1, 2], SureDotOCR must read 3 strings. If 3 strings cannot be read, no results are returned.
Since the default rank for every string model is 0, SureDotOCR tries to read 1 string, regardless of how many string models are in a context, unless you modify rank. In all cases, a maximum of 1 string can be read for each string model.
Space
Space generally refers to the distance between characters. To help deal with spaces in target strings, SureDotOCR allows you to control space settings for string models in a context, by calling MdmrControl() with M_SPACE_SIZE_MIN and M_SPACE_SIZE_MAX. Establishing these settings properly can help differentiate characters in the same string, and characters in different strings.
By default, the minimum space size is equivalent to the maximum character width in the target string. The default maximum space size is equivalent to three times the maximum character width in the string. To disable space settings, set M_SPACE_SIZE_MIN_MODE and M_SPACE_SIZE_MAX_MODE to M_DISABLE.
If the actual space in the target between one character and another is:
Space values are set for a context, so they apply to all strings read for all string models in that context. If you disable the maximum space size, no amount of space between aligned characters can cause them to be part of separate strings. This does not apply to characters on separate lines or severely misaligned characters. If you disable the minimum space size, no amount of space between characters in the same string can cause SureDotOCR to recognize an actual space.
If necessary, SureDotOCR allows you to specify a space as a permitted character constraint. For more information, see the Reading space subsection of this section.
String angle
By default, the angle of a string is detected automatically (MdmrControl() with M_STRING_ANGLE_MODE set to M_AUTO). However, you can explicitly specify the nominal angle at which to read a string. To do so, you must first set the angle mode (M_STRING_ANGLE_MODE) to M_ANGLE; you can then specify the angle using MdmrControl() with M_STRING_ANGLE. Valid values for the angle are specified in degrees, and can range from 0 to 360. The string angle can be set relative to the X-axis of the pixel coordinate system or relative coordinate system; to specify which one, set M_STRING_ANGLE_INPUT_UNITS to M_PIXEL or M_WORLD, respectively. You can also set the angle to the same angle as the target image's region of interest by setting the angle to M_ACCORDING_TO_REGION. A benefit of setting the string angle explicitly is that inspection speed increases if a string angle is chosen and the fixture angle is known.
Alternatively, you can set that the string can be read from left to right with the characters facing upward, or from right to left with the characters facing downward, by setting M_STRING_ANGLE_MODE to M_ORIENTATION. This is useful if the product can be rotated 180 degrees, and this rotation does not affect the acceptability of a product ( for example, if the product is placed backwards at an inspection point but is still a good part).
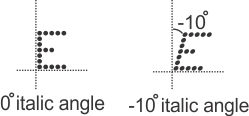
Italic angle
SureDotOCR can also read characters at a specified angle (skew). To do so, you must first set the character angle mode, using MdmrControl() with M_ITALIC_ANGLE_MODE, to M_ANGLE; then, set M_ITALIC_ANGLE to the required angle in degrees. Valid values range from -90 to 90 degrees, relative to a line perpendicular to the angle of the string. The Y-axis is the zero reference (instead of the X-axis), and a positive angle searches for the characters leaning counter-clockwise at a specified angle (left-leaning); whereas, a negative angle searches for the characters leaning clockwise at the specified angle (right-leaning). If M_ITALIC_ANGLE is set to 0, SureDotOCR searches for non-italic characters. A benefit of setting an italic angle explicitly is that inspection speed increases if italic angle is chosen and the fixture angle is known. When M_STRING_ANGLE_MODE is set to M_DEFAULT, M_ITALIC_ANGLE_MODE must also be set to M_DEFAULT.
Constraining string model positions with permitted characters
As previously discussed, any character from any font can, by default, be read at any string model position. For example, if you have two string models (StringGood and StringBetter), each with a maximum and minimum number of characters of two, and you have two fonts (FontNice and FontNicer), each with the characters '2' and '4', the strings '24', '42', '22', or '44' can be read from the target image, where each '2' and '4' can correspond to how they are represented in either font.
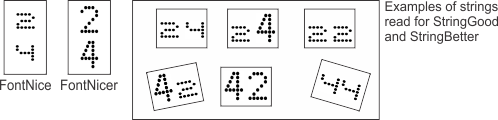
To restrict the characters that can be read, according to a specified character type and font, call MdmrControlStringModel() with M_ADD_PERMITTED_CHARS_ENTRY. This can be considered defining the string's grammar. For example, you can specify that for StringGood, a target string can only be read if the character at position 0 is a '4' from FontNice, and the character at position 1 is a '2' from FontNice. Similarly, for StringBetter, you can specify that a string can only be read if the character at position 0 is a '4' from FontNicer and the character at position 1 is a '2' from FontNicer.
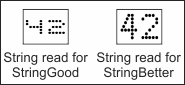
When permitting explicit characters to be read, use M_ADD_PERMITTED_CHARS_ENTRY with M_CHAR_LIST and specify the list of character names, such as "42". If you are using Windows API functions with the Unicode macro, and your source code is also Unicode, you can specify the characters directly in Unicode. Be aware that each character in the list must exist in the specified font. You can also specify character names in hexadecimal format beginning with "\\x", such as "\\x34\\x32" instead of "42". Hexadecimal notation is necessary if you are in an ASCII environment and you want to have Unicode characters beyond the Basic Latin range. For example, Basic Latin does not include the smiley face character; to specify it, use "\\x263A". To list a string of character names with mixed notation, you should also use "\\x" (for example, "ADAMS\\x34\\x32\\x263A").
In addition to permitting one or more specific characters to be read at the different string model positions, you can permit a group of characters to be read. For example, you can permit all digits (M_DIGITS), letters (M_LETTERS), lowercase letters (M_LETTERS_LOWERCASE), and uppercase letters (M_LETTERS_UPPERCASE) that exist in the specified font to be read. You can also permit all characters present in the font to be read (M_ANY). The specified font must contain at least one instance of the characters you are permitting to be read. For example, if you use M_DIGITS, the specified font must have at least one character between '0' and '9'.
All permitted characters in the target, whether you identify them explicitly or as a group, must adhere to their corresponding character definition in either a specific font or in any font in the context. To specify one or any font, use M_ADD_PERMITTED_CHARS_ENTRY with M_FONT_INDEX() or M_FONT_LABEL(). For example, you can permit SureDotOCR to read all digits (M_DIGITS) represented by a specific font (M_FONT_INDEX(n)), or all digits (M_DIGITS) represented by any font (M_FONT_INDEX() set to M_ANY).
M_ADD_PERMITTED_CHARS_ENTRY is cumulative. Each time you specify permitted characters, they are added to the previously specified permitted characters, if they exist. For example, in one call to MdmrControlStringModel(), you can specify the number '1' (with M_CHAR_LIST) as a permitted character constraint at position 0, and in another call to MdmrControlStringModel(), you can specify M_LETTERS as a permitted character constraint at position 0. These two entries allow the number '1' and any letter in the font to be read at position 0. To inquire the number of permitted character entries, call MdmrInquireStringModel() with M_NUMBER_OF_PERMITTED_CHARS_ENTRIES. If this inquire returns 0, it indicates that you have not added any permitted character entries, which means SureDotOCR reads any character from any font (initial default behavior). You can also delete a character constraint at a specific index by calling MdmrControlStringModel() with M_DELETE_PERMITTED_CHARS_ENTRY. You can select to delete a restriction at a specific index, or delete all restrictions.
Reading space
SureDotOCR also allows you to read a space as a permitted character constraint, using M_ADD_PERMITTED_CHARS_ENTRY with M_SPACE. Unlike other permitted characters, M_SPACE has the following restrictions (not following them can cause an error).
Reading an M_SPACE character does not necessarily mean that the corresponding space position in the target string is blank. SureDotOCR attempts to read the best string possible, and can use the space constraint as an area to ignore, even if that area is not empty. For example, if you have an icon at a specific position within a target string, you can specify a space at that position.
Below is a list of examples illustrating how SureDotOCR manages and reads permitted space characters. For simplicity, 'S' refers to space and 'L' refers to letter. Any permitted character other than space could have been used instead of a letter.
|
Target string |
Permitted character constraints |
Will it read? |
|
AB CD |
LLSLL |
Yes |
|
AB CD EF |
LLSLLSLL |
Yes |
|
ABCD |
LLSLL |
No |
|
ABCDEF |
LLSLLSLL |
No |
|
AB CD |
LLLL |
Yes |
|
AB CD EF |
LLLLLL |
Yes |
|
AB CD EF |
LLSLLLL |
Yes |
|
M |
LSL |
Yes |
|
MWM |
LSL |
Yes |
|
In the target string MWM, the letter 'W' can represent numerous types of data, such as another character, an icon, or noise. |
||
 M
MIf an M_SPACE character was read, its resulting character score will be 100% and it will not influence the score of the string. For more information, see the Results and annotations section later in this chapter.
Default permitted characters, and overriding them
If necessary, you can specify permitted characters to read for every string model position. This can prove tedious, as in cases where you want to permit the same characters for the majority of positions in the string model. To handle such cases, and others like it, you can set default constraints for all the positions in the string model by passing M_DEFAULT to the Position parameter, and override the constraints for specific positions by passing M_POSITION_IN_STRING(n) instead, where n is the position for which to specify an explicit (overriding) constraint.
As an example, consider reading the following product lot number:

Here, the dot-matrix string contains 11 characters. With the exception of one character, which is a hyphen, each character can be a digit between 0 and 9. To handle this, you can specify M_DIGITS as the default constraint for all positions in the string model. You can then explicitly specify that at position 5, you want to read a hyphen. This requires calling MdmrControlStringModel() twice, which is a lot more convenient than calling it eleven times.
If you override the default constraints for a specific position, the position is said to be explicitly constrained; otherwise, it is said to be implicitly constrained. In the lot number example above, there is one explicitly constrained position (at position 5).
General controls for the different positions in the string model
SureDotOCR provides general controls for the different positions in the string model. Specifically, you can:
Managing the different string model positions (implicit or explicitly constrained)
The way in which to manage the different string model positions depends on the Position parameter. Specifying M_DEFAULT indicates that you are working with the default constraints for all the positions in the string model (positions that are implicitly constrained). Specifying M_POSITION_IN_STRING(n) indicates that you are overriding the default constraints for the n string model position (that position will then be considered explicitly constrained).
You can also specify M_POSITION_IN_STRING(n) to modify a position (n) that has already been explicitly constrained. Alternatively, you can modify such a position with M_POSITION_CONSTRAINED_ORDER(n), where n indicates the order in which the position was explicitly constrained. For example, if you explicitly constrained positions 19, 5, and 24, their respective constrained order values are 0, 1, and 2.
To control all positions that have been explicitly constrained, use M_ALL_CONSTRAINED_POSITIONS. This can be useful to, for example, add a permitted character constraint to all existing explicitly constrained positions or to reset all explicitly constrained positions to be implicitly constrained (M_RESET_POSITION_TO_IMPLICIT_CONSTRAINTS).
Except for M_ALL_CONSTRAINED_POSITIONS, all Position parameter settings are available for both controlling and inquiring about string models.
If you want to loop through all explicitly constrained positions, call MdmrInquireStringModel() with the Position parameter set to M_POSITION_CONSTRAINED_ORDER(n), where n is the order in which the position was explicitly constrained. Note that the constrained order of a position changes if you reset previously constrained positions to be implicitly constrained (M_RESET_POSITION_TO_IMPLICIT_CONSTRAINTS).
To inquire the number of explicitly constrained positions, use M_NUMBER_OF_CONSTRAINED_POSITIONS.
Recommended conditions for optimal string reading
Sometimes strings you want to read are less than optimal: they could be only part of a string, close to other strings, or dissimilar in dot spacing. To avoid false readings, there are some methods you can use to ensure you are reading the intended strings.
Reading a partial string
If you are only interested in part of a string, the defined string box should be large enough to read the whole string, including the ones you don't want. After reading the entire string, use string related functions to separate the parts of the string you want to read (for example, using a strncpy or std::substr function in C). This avoids problematic results when other strings have the same size in your target image.

Reading only one line of a string with multiple lines
If you are only interested in one line of a string that has multiple lines, you should still read all of the lines in one search region, even the ones you don't want, and then extract the required string line. This helps avoid problematic results.
Reading strings with dissimilar qualities
Multiple strings in an image can sometimes have characters with dissimilar qualities, such as variations in skew angle or spacing between dots. This can occur when, for example, the strings were printed with different ink jets. To prevent inaccurate reading of such strings, use one SureDotOCR context per string model you are looking for, each called to read a different child buffer. If the string can move locations, you can create two child buffers (or more) the size of the entire image, and use a different ROI with each. The following example, illustrates the latter. Two child buffers are set to the size of the whole image; an ROI is set for each such that each encompasses a different part of the string. A different context (with different string constraint) is then used to read each set of strings separately.
