Classifiers and how they work
- See also

 Availability
Availability
 Previous
Previous
- Next

-
A predefined CNN classifier context (M_CLASSIFIER_CNN_PREDEFINED). This classifier context is for categorizing image data (image classification).
-
A tree ensemble classifier context (M_CLASSIFIER_TREE_ENSEMBLE). This classifier context is for categorizing numerical data (feature classification).
Classifiers are the underlying mathematical architectures that must be trained with labeled data. Once trained, you can use the classifier to properly predict the class to which new data belongs.
To train a classifier, you must first allocate its corresponding context. This is done by calling MclassAlloc() and specifying one of the following:
Matrox has predefined several different kinds of CNNs that you can specify upon allocation (M_FCNET_...). Although the underlying structure of these CNNs is generally the same, the sizes of the images and the complexities of the problems they are designed to handle can differ. Typically, the medium size works well in most cases (M_FCNET_M). For more information on these specific classifiers and how to properly train them, see the Predefined CNN classifiers to train subsection of the Training: CNN section later in this chapter.
Note that, unlike predefined CNNs, there are no predefined tree ensembles.
CNN
Theoretically, a CNN is a complex function with millions of weights that, when properly set (successfully trained), establishes the class to which an image belongs. Structurally, a CNN is basically implemented as a cascade of layers, including a source layer, one or more hidden layers, and an output layer.
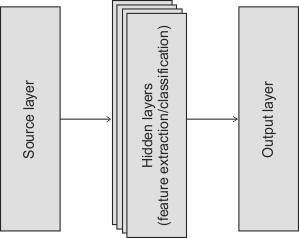
The source layer defines the input size of the network, while the output layer establishes the classes. The hidden layers learn how to classify the image.
Since MIL predefines this classifier architecture, you cannot explicitly control it. Your control lies in training the classifier. During training, MIL establishes the values of the classifier's weights based on your labeled images (training dataset context) and training settings (training context). In this way, the classifier determines the boundaries between classes within a complex internal feature space.
The label of the image identifies the class to which it belongs; this class label is known as the ground truth and is usually established by a human. For example, a human will label numerous images as either GoodApple or BadApple. The training analyzes these labeled images and iteratively adjusts the classifier's weights so it can identify and differentiate the different images with, ideally, a very low error rate (high accuracy). The goal is to establish a stable set of weights such that the trained classifier can classify similar images as well as a human. For more information about the images with which to train, see the Datasets section later in this chapter.
Several settings, which you can specify for the training context, can affect how MIL establishes the classifier's weights. These settings are sometimes referred to as training mode settings. Examples of such settings include the learning rate and the number of training cycles (epochs). For more information about training settings, and how to train a CNN, see the Training: CNN section later in this chapter.
Image classification
You would typically train a predefined CNN classifier context to predict that an entire image is either good or bad (such as GoodApple or BadApple), or to predict that an entire image as one of several possibilities (such as Apple, Orange, or Pear). The following example shows three images, one of which is classified (predicted) as belonging to the GoodApple class, while the other two are classified as belonging to the BadApple class.

Rather than classifying the entire image, you can also perform a coarse pixel level classification of the image. This is known as coarse segmentation and represents a more advanced approach to using a predefined CNN for classification. Typically, coarse segmentation is done when you want to detect defects on an object's surface, such as bruises on apples or scratches on metal sheets. For more information, see the Coarse segmentation subsection of the Advanced techniques section later in this chapter.
Note, it is possible to use a pretrained CNN. In this case, Matrox designs, builds, and also trains the classifier context to address your needs according to the labeled images that you provide. Once Matrox sends you this pretrained classification context, you can restore and use it. If you are interested in a pretrained CNN, contact customer support.
Tree ensemble
A tree ensemble classifier is a set of decision trees. A decision tree is a collection of nodes connected by branches. Each node takes in data and either makes a decision on how to best split (branch) the data into 2 other nodes, or makes a final decision on that data (known as a leaf node). Starting with a single node, the data gets processed down the tree until it is no longer splittable and all branches end with a leaf. Those leaves can be considered the classes.
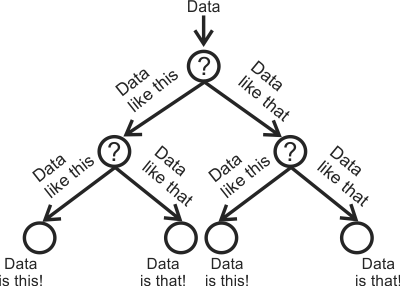
Feature classification
MIL's tree ensemble classifier is designed to classify numerical data. Typically, this numerical data traces back to features in images, though you do not specify images to train this classifier.
For example, if you have numerous images with basic geometric shapes, you can use the MIL Blob Analysis module to extract features from those shapes, such as their convex hull, elongation, and perimeter. The values associated to those features represent the kind of numerical data that you would use with a tree ensemble classifier (as opposed to a CNN, which would use the actual images with the shapes).
For training purposes, you must feed the classifier numerous sets of feature values, such as convex hull, elongation, and perimeter. Each set is an entry in a features dataset and must be labeled with the class that represents the data. For example, you could have 4 classes called Circle, Ellipse, Square, and Rectangle. In your dataset, you would provide hundreds of entries that contain feature values (such as convex hull, elongation, and perimeter) and each of those entries would have the label of the class (shape) those features represent.
By taking in the labeled sets of feature values, the classifier learns the criteria with which to split the data, node by node, until it is able to properly identify the class that best represents that data (the feature values). Once such a classifier is trained, it should be able to properly identify any similar data that you give it.
Rather than using just one decision tree, tree ensembles use many. Each tree takes in and classifies the same set of features; the final classification decision is based on the decision of the majority of the trees. To process the features, node by node, tree ensembles use bagging, randomness and multiple learning algorithms (bootstrap aggregating) during the training process. For more information, see the Training: tree ensemble section later in this chapter.